
Praca z danymi nie polega już na samym wpisywaniu liczb do arkusza. Liczy się cały łańcuch: od zebrania informacji, przez ich oczyszczenie i zestawienie, aż po wniosek, który da się obronić przed szefem, klientem albo prowadzącym projekt. W tym tekście pokazuję, jak wygląda analiza danych, jakie programy komputerowe naprawdę się przydają i jak dobrać je do celu, poziomu oraz rodzaju zadania.
Najważniejsze jest dopasowanie narzędzia do etapu pracy i rodzaju wyniku
- Najpierw określ pytanie, a dopiero potem wybieraj program.
- Do szybkich zadań wystarczy Excel, ale do pracy cyklicznej lepiej sprawdzają się SQL i narzędzia BI.
- Python i R przydają się wtedy, gdy potrzebujesz automatyzacji, większej kontroli albo statystyki.
- Największy błąd to mylenie wizualizacji z interpretacją.
- Dobre dane wejściowe są ważniejsze niż efektowny dashboard.
Co dzieje się w procesie pracy z danymi
Ja zwykle tłumaczę to tak: najpierw trzeba zrozumieć pytanie, potem sprawdzić źródła, a dopiero na końcu wybrać program. Sama obróbka liczb nie wystarcza, bo dane bez kontekstu łatwo prowadzą do fałszywych wniosków. W praktyce cały proces składa się z kilku etapów, które powinny układać się w logiczną sekwencję, a nie w zbiór przypadkowych działań wykonywanych na szybko.
- Definiuję problem - ustalam, co dokładnie mam sprawdzić, porównać albo przewidzieć. Inaczej wygląda zadanie „dlaczego sprzedaż spadła”, a inaczej „który kanał daje najlepszy zwrot”.
- Wybieram źródła informacji - sprawdzam, skąd pochodzą dane, czy są kompletne i czy opis pól jest zrozumiały. Bez tego nawet najlepszy raport może być mylący.
- Czyszczę i porządkuję dane - usuwam duplikaty, poprawiam formaty dat, ujednolicam nazwy i sprawdzam braki. To nudny etap, ale zwykle właśnie on decyduje o jakości wyniku.
- Eksploruję zbiory - patrzę na rozkłady, trendy, odstające wartości i zależności między zmiennymi. Ten moment często pokazuje pierwsze rzeczywiste hipotezy.
- Porównuję i interpretuję - nie zatrzymuję się na wykresie, tylko sprawdzam, co z niego wynika i jakie są ograniczenia wniosku.
- Prezentuję wynik - przygotowuję raport, tabelę, dashboard albo krótkie podsumowanie dla osób, które podejmują decyzję.
Jeśli ten porządek się rozmywa, nawet dobre narzędzie zaczyna przeszkadzać zamiast pomagać. Kiedy już widać, z czego składa się cały proces, łatwiej ocenić, które programy wspierają go najlepiej.
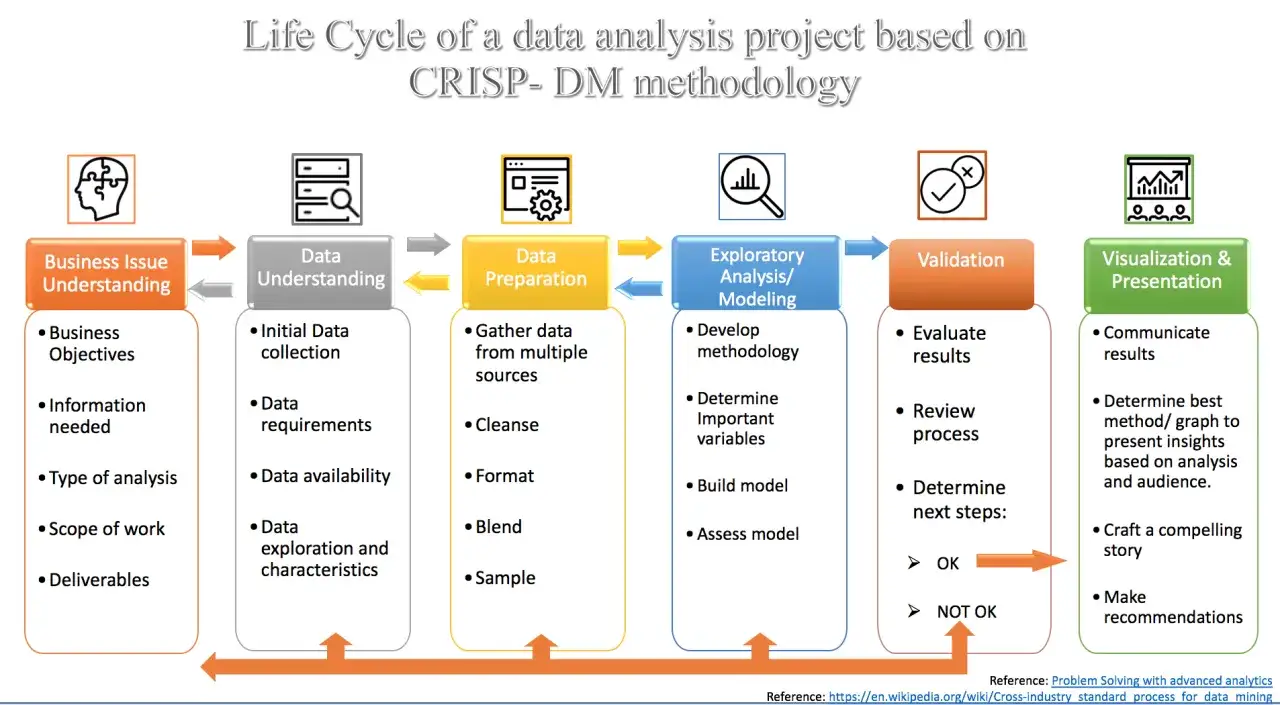
Jakie programy naprawdę przydają się przy pracy z danymi
Tu najczęściej pojawia się nieporozumienie: wiele osób wrzuca do jednego worka arkusze, bazy danych, narzędzia BI i języki programowania. Ja patrzę na to inaczej. Jedne programy służą do szybkiego porządkowania informacji, inne do pracy na dużych zbiorach, a jeszcze inne do raportowania i automatyzacji.
| Program lub kategoria | Do czego służy najlepiej | Mocne strony | Ograniczenia | Kiedy się sprawdza |
|---|---|---|---|---|
| Excel lub arkusz kalkulacyjny | Szybkie porządkowanie, filtrowanie, tabele przestawne, niewielkie analizy | Niski próg wejścia, szybko widać efekt, łatwy start | Trudniej automatyzować, łatwo o ręczne błędy, słabsza kontrola wersji | Na początku nauki, przy jednorazowych zadaniach i prostych raportach |
| SQL | Pobieranie, łączenie i agregowanie danych z baz | Precyzja, szybkość, dobra praca na dużych zbiorach | Nie zastępuje wizualizacji ani pełnej analizy statystycznej | Gdy dane są w systemach, hurtowniach lub kilku źródłach naraz |
| Power BI, Tableau, Looker Studio | Raporty, dashboardy, interaktywna prezentacja wyników | Czytelność, filtrowanie, udostępnianie innym osobom | Mniejsza elastyczność przy nietypowych obliczeniach i modelach | Gdy odbiorca ma szybko zrozumieć wynik i sam go przeglądać |
| Python z biblioteką pandas | Czyszczenie, automatyzacja, modelowanie, eksperymenty | Duża kontrola, wiele bibliotek, powtarzalność pracy | Wymaga nauki kodu i dyscypliny w organizacji projektu | Gdy chcesz regularnie wykonywać te same zadania lub budować skrypty |
| R | Statystyka, wizualizacja, praca badawcza | Mocny aparat statystyczny, dobre narzędzia graficzne | W części zespołów biznesowych jest mniej popularny niż Python | Gdy priorytetem jest klasyczna statystyka i analiza badawcza |
W praktyce najczęściej nie wybiera się jednego narzędzia, tylko zestaw. Excel bywa dobrym punktem startowym, SQL porządkuje dostęp do danych, a Power BI albo Tableau pokazują wynik w czytelnej formie. Python i R wchodzą do gry wtedy, gdy potrzebujesz większej kontroli, powtarzalności albo bardziej zaawansowanej statystyki. Sam model pracy jest ważniejszy niż marka programu.
Jak dobrać narzędzie do poziomu i zadania
Jeżeli miałbym uprościć wybór, zrobiłbym go według trzech pytań: czy potrzebujesz szybko zobaczyć wynik, czy chcesz go regularnie odświeżać i czy planujesz automatyzację. Odpowiedzi na te pytania zwykle mówią więcej niż lista funkcji w folderze sprzedażowym.
Gdy zaczynasz od prostych zadań
Na start wystarczy arkusz kalkulacyjny, podstawy formatowania danych i umiejętność tworzenia wykresów. To daje szybki feedback i pozwala zrozumieć logikę pracy, zanim wejdziesz w kod. Dobrze jest też dorzucić podstawowy SQL, bo już wtedy widać, jak dane są pobierane i łączone.
Gdy raport ma trafiać do innych osób
Wtedy lepiej sprawdzają się narzędzia BI. Dashboard powinien być prosty, czytelny i aktualizowany bez ręcznego przepisywania liczb. Tu ważna jest nie tylko estetyka, ale też spójna definicja metryk, możliwość filtrowania i pewność, że każdy widzi tę samą wersję raportu. To szczególnie przydatne w sprzedaży, marketingu i finansach.
Przeczytaj również: Jak przekreślić tekst w Wordzie - proste metody, które musisz znać
Gdy chcesz skalować i automatyzować
Jeśli zadanie powtarza się co tydzień albo co miesiąc, warto sięgnąć po Python lub R oraz uporządkować cały proces w skryptach. Dzięki temu ograniczasz ręczne poprawki, łatwiej też odtworzyć wynik i sprawdzić, co dokładnie zostało policzone. To rozwiązanie wymaga więcej nauki, ale zwykle zwraca się bardzo szybko, gdy pojawia się większa liczba danych lub wiele źródeł.
Najczęstszy błąd polega na tym, że ktoś uczy się zbyt ciężkiego narzędzia do bardzo prostego zadania albo przeciwnie - próbuje ręcznie robić coś, co powinno być zautomatyzowane. Gdy narzędzie jest już dobrane, warto zobaczyć, jak prowadzić pracę krok po kroku.
Jak prowadzić pracę krok po kroku, żeby wynik miał sens
Ten etap lubię najbardziej, bo tu widać, czy zespół naprawdę rozumie własne dane, czy tylko je przetwarza. Dobra kolejność działań ogranicza chaos i zmniejsza liczbę błędów, które później wychodzą w prezentacji albo raporcie.
- Ustal decyzję, którą chcesz wesprzeć - najpierw pytanie, potem narzędzie. Bez tego łatwo zbudować ładny raport, który niczego nie wyjaśnia.
- Sprawdź źródła i zakres danych - określ, z jakiego okresu pochodzą informacje, jakie mają ograniczenia i czy obejmują cały interesujący obszar.
- Przygotuj dane do pracy - ujednolić nazwy, typy pól, daty i identyfikatory. To moment, w którym porządek robi największą różnicę.
- Zrób eksplorację - policz podstawowe statystyki, sprawdź rozkłady i porównaj segmenty. Tu często wychodzą pierwsze różnice, których wcześniej nie było widać.
- Zweryfikuj hipotezy - jeśli wynik ma znaczenie decyzyjne, nie opieraj się wyłącznie na intuicji. W wielu przypadkach przydają się testy statystyczne, korelacje albo proste modele predykcyjne.
- Przygotuj wizualizację i wniosek - wykres ma ułatwić zrozumienie, ale to wniosek ma zamknąć temat. Dobrze jest też dodać informację, czego ten wynik nie obejmuje.
- Zadbaj o powtarzalność - jeśli proces ma wracać, opisz go albo zautomatyzuj. To oszczędza czas i zmniejsza ryzyko, że za miesiąc nikt nie odtworzy tego samego wyniku.
Jeżeli chcesz powtarzać taki proces co tydzień lub co miesiąc, właśnie tu najbardziej opłaca się inwestować w automatyzację. To prowadzi prosto do pytania o błędy i ograniczenia, bo programy nie rozwiązują wszystkiego same z siebie.
Najczęstsze błędy, które psują wyniki
Z mojej perspektywy większość problemów nie wynika z braku zaawansowania, tylko z pośpiechu i złych nawyków. Poniżej są błędy, które widzę najczęściej, zwłaszcza u osób uczących się pracy z danymi.
- Zaczynanie od narzędzia, a nie od pytania - wtedy raport powstaje szybciej niż sensowny wniosek.
- Ręczne poprawki bez śladu - jeśli nie wiesz, co zostało zmienione, nie odtworzysz wyniku i trudno go obronić.
- Za dużo wskaźników naraz - nadmiar metryk zwykle rozmywa obraz zamiast go wzmacniać.
- Mieszanie definicji - ten sam „klient aktywny” albo „przychód” potrafi znaczyć coś innego w różnych działach.
- Odpowiadanie wykresem zamiast wnioskiem - obrazek bez komentarza rzadko pomaga podjąć decyzję.
- Ignorowanie jakości danych - brakujące wartości, duplikaty i błędne daty potrafią całkowicie wypaczyć wynik.
- Zaawansowany model przy zbyt małej potrzebie - czasem prostsza agregacja daje lepszą odpowiedź niż skomplikowany algorytm.
Im bardziej powtarzalna ma być praca, tym bardziej trzeba pilnować jakości wejścia, definicji metryk i opisu transformacji. Kiedy te trzy rzeczy są pod kontrolą, łatwiej przejść od jednorazowego projektu do sensownej ścieżki rozwoju.
Od pierwszego raportu do stabilnej kompetencji
W 2026 najrozsądniej budować kompetencje warstwowo. Najpierw opanować arkusz i podstawy wizualizacji, potem SQL, a dopiero później Python albo R, jeśli praca tego wymaga. To nie jest kwestia prestiżu narzędzia, tylko efektywności: lepiej mieć prosty, działający zestaw niż ambitny, ale niedokończony warsztat.
- 2-4 tygodnie - podstawy Excela, filtrowanie, tabele przestawne i proste wykresy.
- 4-6 tygodni - SQL, agregacje, joiny i podstawowe zapytania na kilku tabelach.
- 4-8 tygodni - pierwszy dashboard w Power BI, Tableau albo Looker Studio.
- 2-4 miesiące - Python z pandas do czyszczenia, łączenia i automatyzacji danych.
- 3-6 miesięcy - własne projekty, które pokazują cały proces od surowych danych do wniosku.
Jeśli miałbym wskazać jedną zasadę, powiedziałbym tak: zaczynaj od prostego narzędzia, które pozwala dowieźć efekt, a dopiero potem dokładaj kolejne warstwy. Dobra analiza danych zaczyna się od jasnego pytania i kończy na wniosku, który ktoś może wykorzystać w decyzji - reszta jest tylko środkiem do tego celu.